The following is my attempt at explaining the process for my project on a pitch prediction neural network model based on a screenshot at the moment of a pitcher breaking his hands. The class on fastai I’m currently taking recommended writing as a reinforcing tool for learning. This coincided with my own initiative to start a parallel project to help me learn more efficiently so this is sort of the culmination of a couple of different techniques to hopefully expedite the learning process.
The initial example that was used in the course was of a neural network accurately identifying bears into grizzly, black and teddy bear categories based only on the images and it’s training. The initial lessons focused on the process of saving, scraping, labeling and feeding the model the image data it needs to learn. Following along in a jupyter notebook, I was able to pick up enough parts of the information to attempt to build my own model. One of the learning tactics the class used was giving the student essentially the whole picture all at once and then going back and fine tuning, as opposed to a ground up technique that focuses on the details and build on that for the next lesson. I wholeheartedly agree with the approach of all at once and go back. Similar to the maxim in board games where when a person is learning the game for the first time, you have to tell them “this is how you win” and then go back and explain it with that in mind.
I don’t know how the idea came to me for my project, aside from having the thoughts before that in the future it would certainly be the case that teams would be using AI to identify value and one of the ways was that AI would be able to tell what pitch was being thrown based on the windup before it happened. It suddenly came to me that I might as well try my hand at a rudimentary janky first model.
The Goal:
The purpose was not to create a proprietary model that would be a world class image recognition tool for MLB teams. The goal was to find a topic that interested me and apply the tools I was learning about to something fun – accelerating the learning process and getting into the weeds to better understand the topic using my domain knowledge.
The Project:
My hypothesis was that with enough image data, a neural network would be able to identify “tells” and predict with high accuracy what pitch the pitcher was going to throw before release. In professional baseball, there are times when hitters can pick up on a pitchers tell with their eyes. “When he throws a curveball he always drops his hands.”
This video is a bit lengthy but a good primer:
My thoughts were, if professional baseball players could pattern recognize well enough to get and edge certainly an image recognition model would, at some point, do better.
Initially, the plan was to save video data as a gif and feed that interlaced image data to the model to interpret. This technique is currently above my skill level so I pivoted to a still images to feed that model. I debated at what point to capture the pitcher. My first idea was “at release”, but I ended up landing on an image of when the pitcher breaks his hands (the moment when you can first see separation between the hand holding the ball and the glove). My reason for this was anecdotally it seems like a point that was easily repeatable to capture manually and based on my time pitching, a point where there might be discrepancies with relation to body positioning and posture that the network might pick up.

For the limited scope of testing this hypothesis, I was going to limit myself to analyzing just one pitcher. The time needed to gather the image data meant I had to have a small scope, and the model will only be effective at analyzing and predicting based on a single pitchers tendencies so I chose Max Scherzer. I landed on him for a couple of reasons; personally I am biased towards him as a fan, he is a recognizable pitcher, and he throws 5 pitches with a good speed mix (4 seam fastball, cutter, slider, changeup, curveball) and a good usage mix which meant I was going to have a more diverse image data set than if I had chosen someone with a small pitch range.
The next major and necessary step for improving and further testing is to automate the collection of screenshots to be able to collect on the scale necessary.
Gathering the Data:
Next, I needed an easy way to collect the initial images.
Baseball Savant has a player page for Max Scherzer where you can hit a “random video” button. This pulls up an 8-15 second clip of a random pitch from his career from 2018-present. In those videos, I would manually pause and skip to the moment as best I could, where his hands were separated. Very time consuming, yes, but at this stage of the project I was just excited to have my own idea and exploring the project. From there I would also manually assign what pitch was thrown and whether it was from the windup or the stretch (as a former pitcher I knew there were bound to be differences in the same pitch group for those two categories so I felt it was important to label that as well) , and save the screenshot in the appropriate folder/sub folder. The size of the mini project was small enough to be able to use my local file system. Once scaled up, the storage question would be another one I would have to answer.
From there I just took the time to manually click random video and save it appropriately. After the folder had about 100 total images, I made some modifications to how I was filtering the videos. I stopped saving data from the 2018 season, as the frames per second quality made it difficult to stop the video with high enough accuracy. I also tried to not use camera shots from directly behind the mound as I felt that would skew the results because of the fairly stark perspective difference and guessing that it might throw the model off unnecessarily when there was basically an unlimited amount of camera angles from slightly off center.


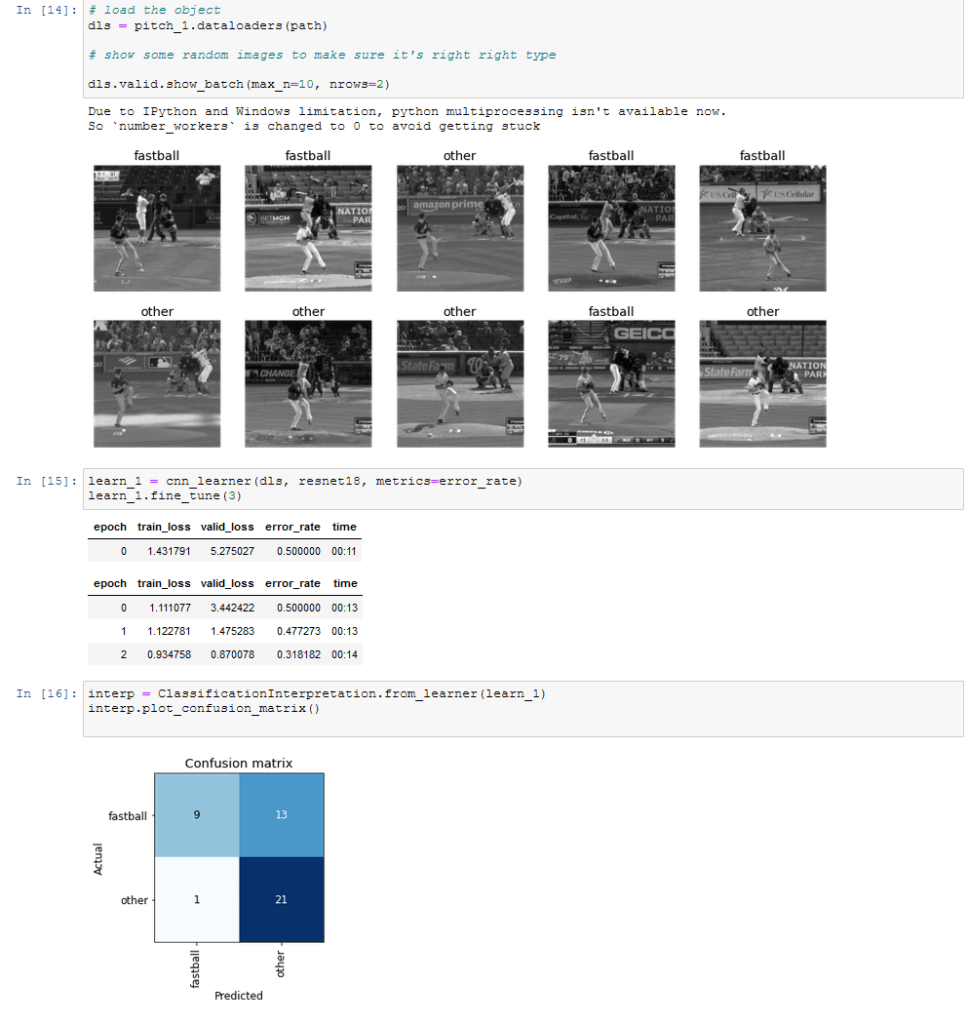
Initial Tests/Learning to use fastai

Above was the first test. This is where I classified pitches as “fastball” and “other” to see if there were any tells when he was throwing a fastball and and when he was throwing off-speed. In terms of attempting to get actual results, this test was incredibly premature. A tiny sample size and really no further image tidying. I was just excited to try it out and enjoyed seeing the results and planning further improvements.
Next idea was to change all of the images to gray:
Cropping
The next move, as I was looking at the results of the first trial tests, was to crop the image down to just the pitcher. My thoughts being that the model did not know I wanted it to focus on the pitcher, and that it if I was asking it to look for minute changes in the posture of the pitcher, but was including the crowd, umpire, catcher and batter, it was unrealistic to think it would pick up on it.
My first attempts at cropping were rudimentary and unsuccessful:

Based on the test images it looked like it might be a slight improvement – once I batch edited the folders I saw how poorly that crop performed.
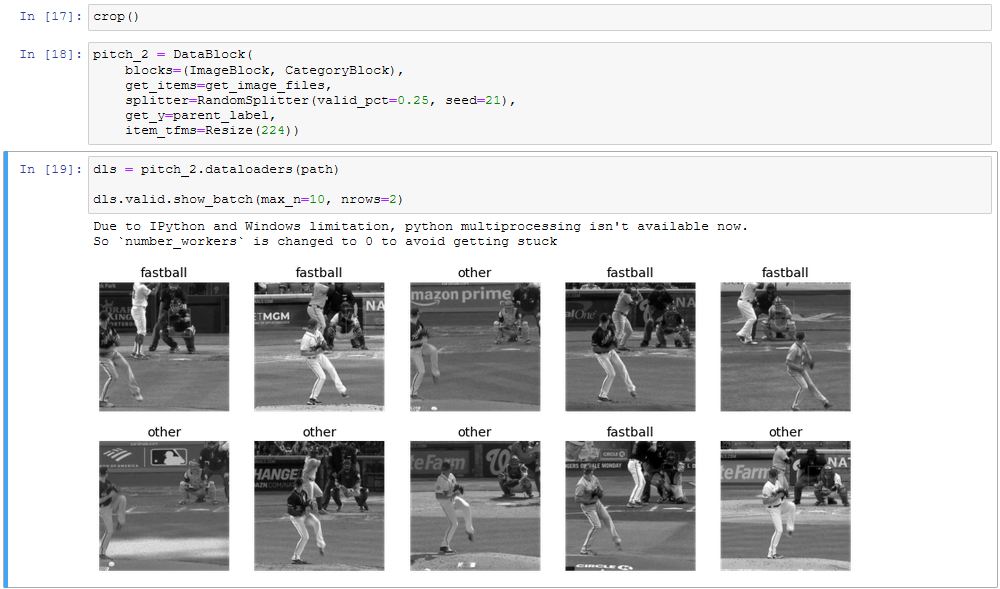
YOLOv4
I realized I would be stuck if I was unable to find another way to accurately crop just the pitcher on a large scale and programmatically. This lead to some research and to find a way to detect objects within the image. This lead me to some youtube videos about object detection and classification using YOLOv4.
Which lead me here:
https://github.com/theAIGuysCode/yolov4-custom-functions
I borrowed a lot of code from the above project to better understand the processes.
I knew nothing about the subject but it showed once again the utility of doing these types of projects on your own. You’ll come to an obstacle and have to wade into unfamiliar waters to try to find a solution, oftentimes that wading is where my knowledge base has its largest gains. So knowing an object detection network existed, I now had to familiarize myself and learn how to use it.
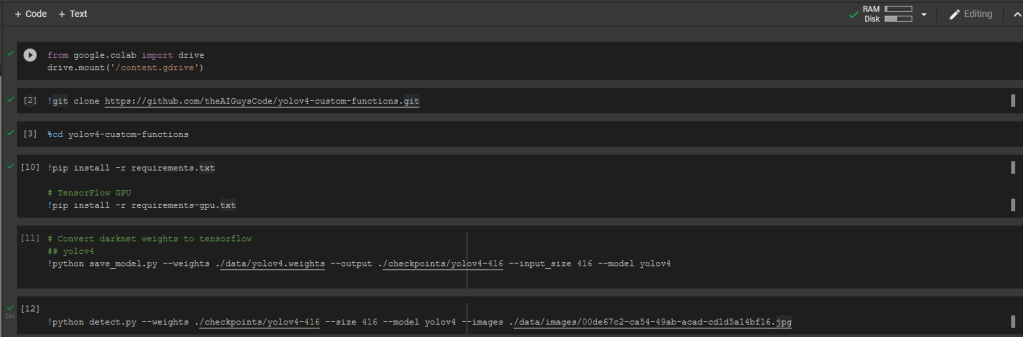
The initial runs for detecting objects resulted in outputs that looked like this:
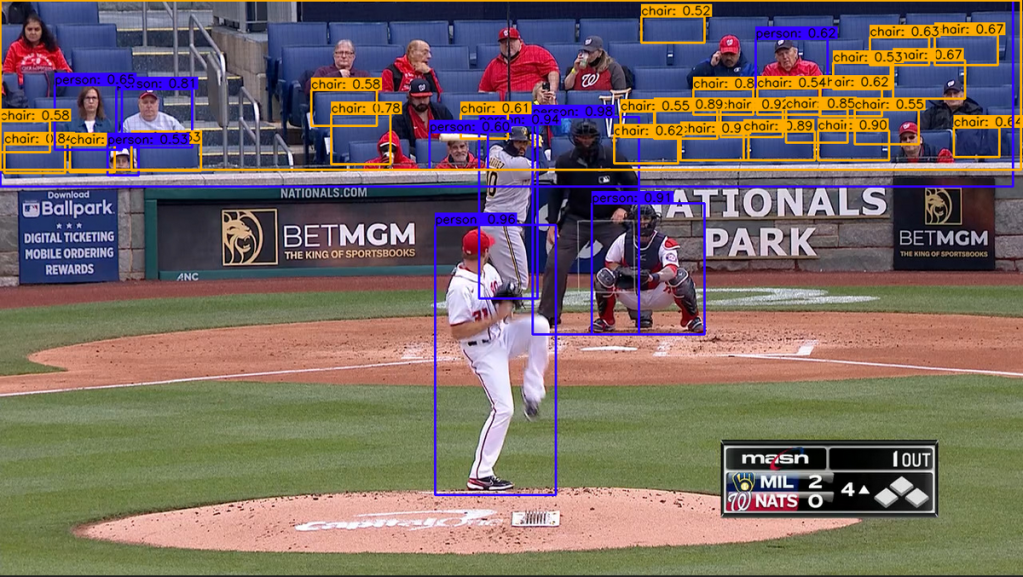
So now I went into the functions running the detection and made some changes. First, I edited the code to only allow “person” to be detected, trying to remove the noise of other objects. Resulting in a cleaner but not perfect output.
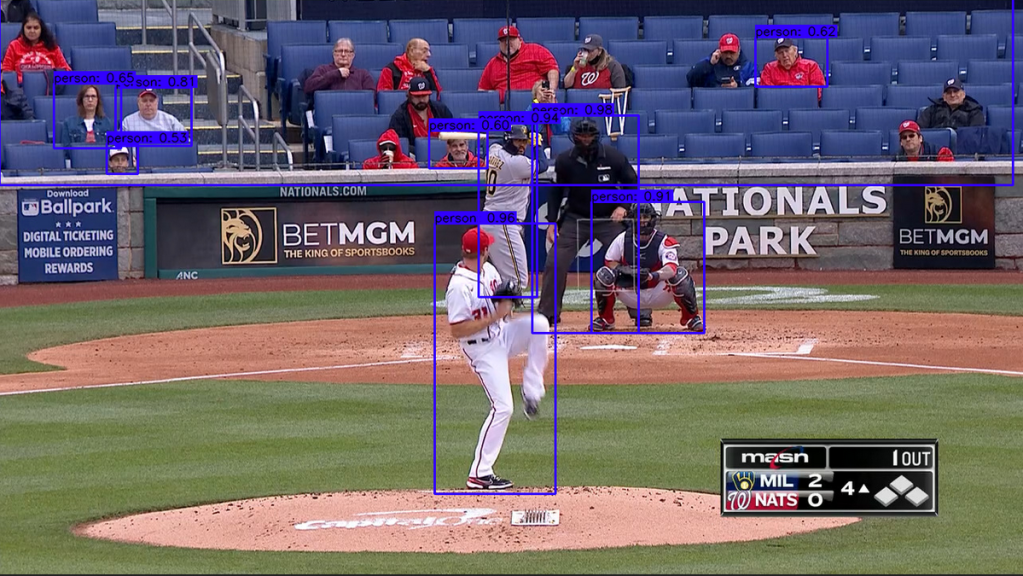
Next I turned up the score needed for the model to detect an object. The confidence which it needs by default to classify an object is about 50%. For the images I was going to use, the ‘person’ it would identify as the pitcher would be above that confidence.
In the new detect_person file. The confidence is set at .93.
The hope now is that the fans in the background will largely be excluded in the detection.
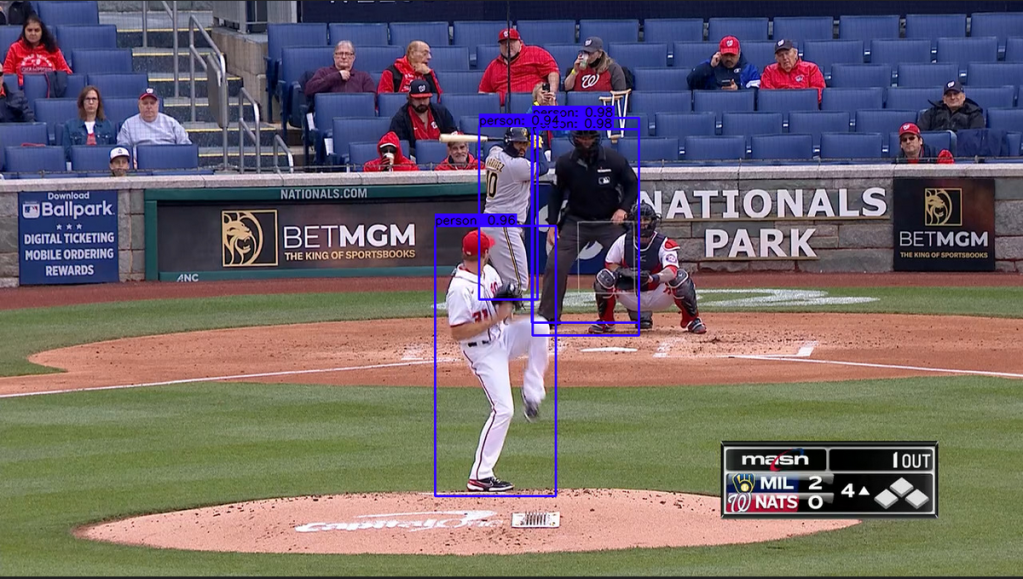
Getting better. I hit a road block at this point and was not able to figure out the best way to teach it specifically what a ‘pitcher’ was compared to other persons. I went down the route for a while to make a custom model to recognize pitchers, and that would be the best route once the proof-of-concept was complete to scale the project, but for my purposes I went once again manual.
Next I added a function in the routine to crop out all of the bounding boxes yolo detected and store them in the appropriate folders.
I fed my folders of images through and manually edited the images to delete any non pitchers.
From there I loaded ran the fastai model again with the cropped and greyed images of fastball/nonfastball.
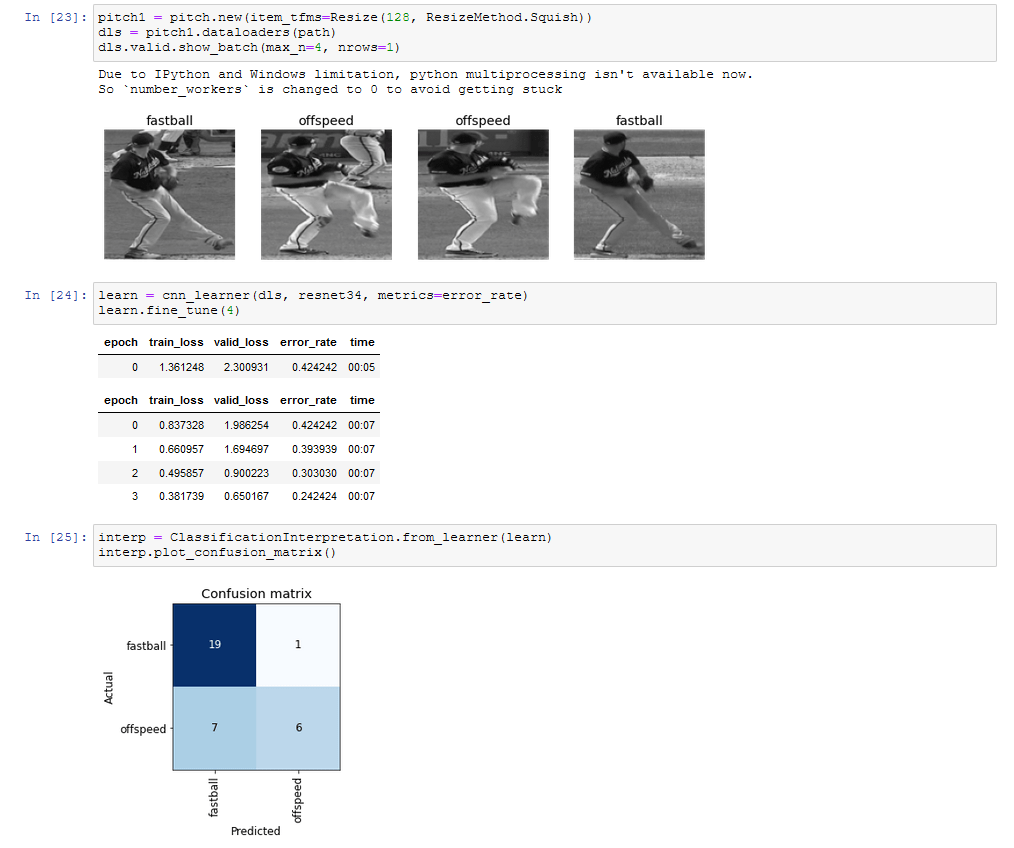
Better results, but in the end fairly meaningless for such a small sample size.
Conclusions
The goal of the exercise was to speed up the learning process by choosing a project with which I could apply domain knowledge and get excited about. I think I accomplished that goal. One of the great byproducts of doing these projects to enhance learning is that you almost always end up learning another tool in the process. Inevitably you’ll get to an obstacle and are forced to add another tool to the tool belt to solve it. In this case, yolov4. I think that mechanic of learning goes to show project based education, at least for me, is a huge catalyst for growth and one that’s exciting.
